There is an endless sea of data available to nearly everyone. The problem is that, for the most part, that data is basically useless without having someone or something able to interpret that data.
For AI to be used effectively in our future, we need companies now to start labeling this endless amount of data. Not only number and datasets, but real images and video, as well. Think of Google and signing in to your email. Ever had to identify yourself by pointing out what images contain a car?
It’s kind of like that, but on a much, much larger scale.
That’s where companies like Hive come into play. They take huge amounts of image and video data and through “the world’s largest distributed workforce of human data labelers,” make datasets that actually mean something.
I had the chance to speak with Kevin Guo of Hive to discuss the service, what inspired it, and where he sees data going in the future.
Check out the interview below.
Care to introduce yourself and your role at Hive?
My name is Kevin, and I’m the CEO / Co-founder of Hive. Prior to this, I studied CS at Stanford (BS/MS) and worked in venture capital.
In a few sentences, what is Hive?
Hive understands the world’s visual data. We build vision models that take in raw image and video, and output structured data (i.e. finding objects, people, logos, etc).
What makes us unique is that we also operate the world’s largest distributed workforce of human data labelers, each contributing microtasks to an enormous labeled dataset (hence the name Hive).
What inspired Hive?
My co-founder and I started this when we were both grad students at Stanford in a machine learning course. We felt that while there were a lot of exciting developments in AI, there weren’t many practical companies being built. Our core thesis was that without a large amount of quality data, building usable models wouldn’t be possible.
We spent the first few years of the company gathering data and building our distributed data labeling platform (which is now Hive Data). Today, Hive Data is not only driving all of our models internally but also used heavily by many other companies for their own machine learning needs.
Who would you consider the competition, and what do you believe separates you from them?
There are many companies operating in the AI space, but we believe there are virtually no companies out there operating both a significant data labeling operation as well as enterprise-grade model building.
Our full-stack approach allows us to build specialized models such as our NSFW and logo models, that outperform our competitors. Hive Data has over 500,000 workers and collectively we’ve labeled over 2 billion pieces of data.
We don’t use any open source datasets and all of our vision models are trained on datasets that are each the largest in the world. Our ability to label our own data is a huge differentiator.
Last year, AngelList called you one of the most competitive startups to work for. How did that happen?
We’ve always believed that the key to building a lasting company in a space as technically challenging as AI is to hire the best talent. In our case, we’ve focused on both hiring great ML researchers as well as strong engineers.
A lot of what we do is not what you would consider pure ML research, but rather focusing on the other sides of ML: building Hive data, working on distributed training systems (due to the sheer size of our training data), and deploying our models across hundreds of GPUs to serve the billions of requests we process per month.
What do you think of the state of the AI industry at present?
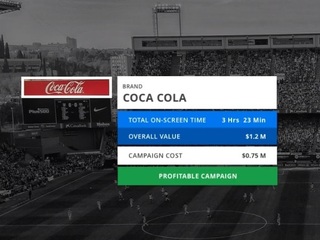
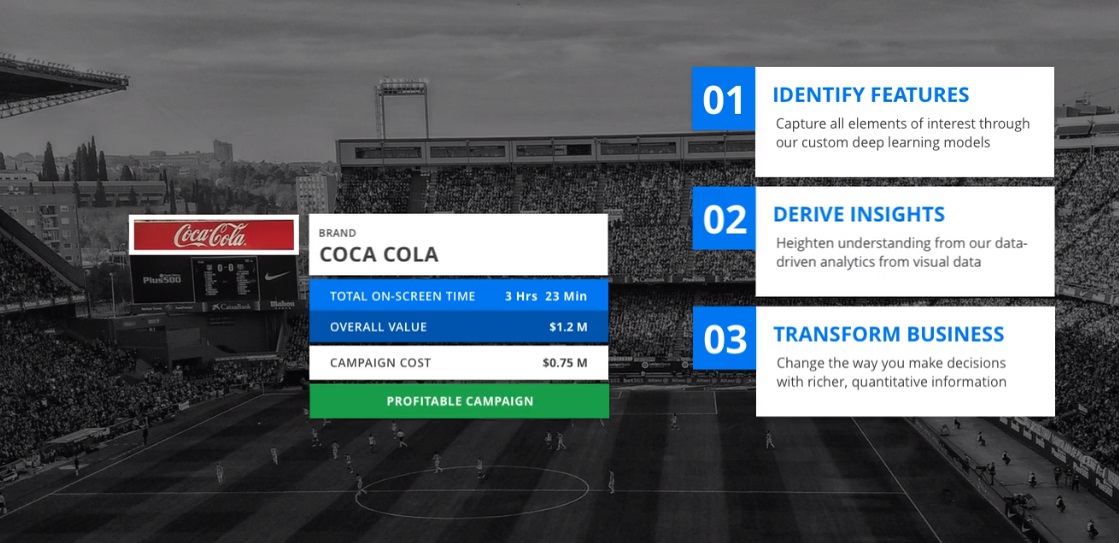
I think there is a common misconception that much of AI, in particular, deep learning vision models, is a commodity service. For instance, one of our core models today is our logo model, which identifies thousands of different brands in images/videos.
From the marketing materials of some of the large tech companies out there, one would think this is a solved problem. In fact, when we compare our models with the competitors’, we find that our performance is not just a little better: we find that we are orders of magnitude better.
The truth of the matter is that AI is still very much in its infancy, and there are very few enterprise-grade products on market today. For us, this is where we’ve had such great product/market fit. Our customers have tried all of the typical platforms you would imagine, and they’ve been disappointed by what they actually see. When they access our platform, they experience models that are not just better than other AI models: we are now often exceeding human accuracy.
What are the unique challenges of computer vision in AI?
There are two phases to building an AI model: 1) collecting a dataset of sufficient diversity and quality to represent the domain, and 2) building some sort of model framework that can actually train on this data to achieve the desired output.
Most people focus on 2) and underestimate the value of 1). Computer vision, especially using deep learning techniques, is highly unique in that the data requirements can be enormous. Without a sufficiently large dataset, no amount of tweaking of the underlying model will help.
Many AI startups use open source datasets like imagenet which has ~13m labeled images. In our experience, AI models require a significantly larger number of well-labeled images to be of value. Hive’s AI models are built on top 2b+ labeled images and we are adding tens of millions of images to our corpus every week.
The self-driving car industry is slowly starting to appreciate the value of large datasets for developing AI models, but it doesn’t appear the industry is anywhere near the level they need to be to create safe products.
We still talk to start-ups that have raised 10s of millions of dollars from leading venture funds that are planning to build AI models on millions of labeled items. The leading self-driving car companies are investing large amounts in creating large labeled datasets, and they are often partnering with Hive as we have the world’s largest data labeling infrastructure.
Anything else to add?
I think of the problem of building computer vision models in 4 broad buckets, and our competitive advantages in each are listed here:
1. Collecting large amounts of training data. We have the world’s largest distributed workforce of human data labeling for computer vision applications, and we’re able to get incredibly vast and high-quality data at a fraction of the cost of competitors since this is our own service.
2. Developing the suitable model for the problem. It turns out that once you have the data, choosing the right model itself is not necessarily an easy problem. For certain models, we’ve iterated through dozens of different combinations of frameworks before finding the right approach. This requires having ML researchers on staff with years of experience who can understand all the published literature and are able to push the bounds of research.
3. Efficient training. Most people don’t encounter this because they haven’t followed 1), but a new bottleneck quickly emerges once you operate at the scale Hive does: the actual time it takes to train a model becomes a real challenge. For instance, some of our detection models are trained on 10s of millions of bounding boxes — a naive approach using a single GPU might take months. We’ve built distributed training systems across multiple machines and multiple GPUs that can reduce this to days. Doing this speedup while maintaining model quality output is a non-trivial task.
4. Efficient deployments. Running neural net models in production is another challenge that, given the immaturity of the market, is another challenge we’ve had to overcome on our own.
Today, we are processing billions of requests a month to various computer vision models, and the ability to load balance these across GPUs is a custom system that took us years to develop. Aside from the large tech giants, we are probably one of the biggest deployments of deep learning models in the world, and have had to push the bounds of engineering to achieve this scale.
I’d like to thank Kevin for taking the time to answer some of my questions regarding AI and data.